
从零开始的Transformer重新学习
前言
从零开始,指的是深度学习已经完成基本入门,到了解MLP的结构和训练过程为止。仔细想来,我自己连RNN也不算非常熟悉,故从零开始回顾。本文中的Transformer如无特殊说明,为经典的NLP领域的Transformer。
我认为了解一个方法的最快方式是给出该方法的高级抽象。总的来说,Transformer的整个完整方法,输入是一段话,不限语言。输出是另一段话,同样不限语言。Transformer的目的是学习输入输出语句的内在关系,所以自然的,可以用于不同语言的转换(翻译任务)、以及上下句的转换(对话任务)。
模型结构与实现
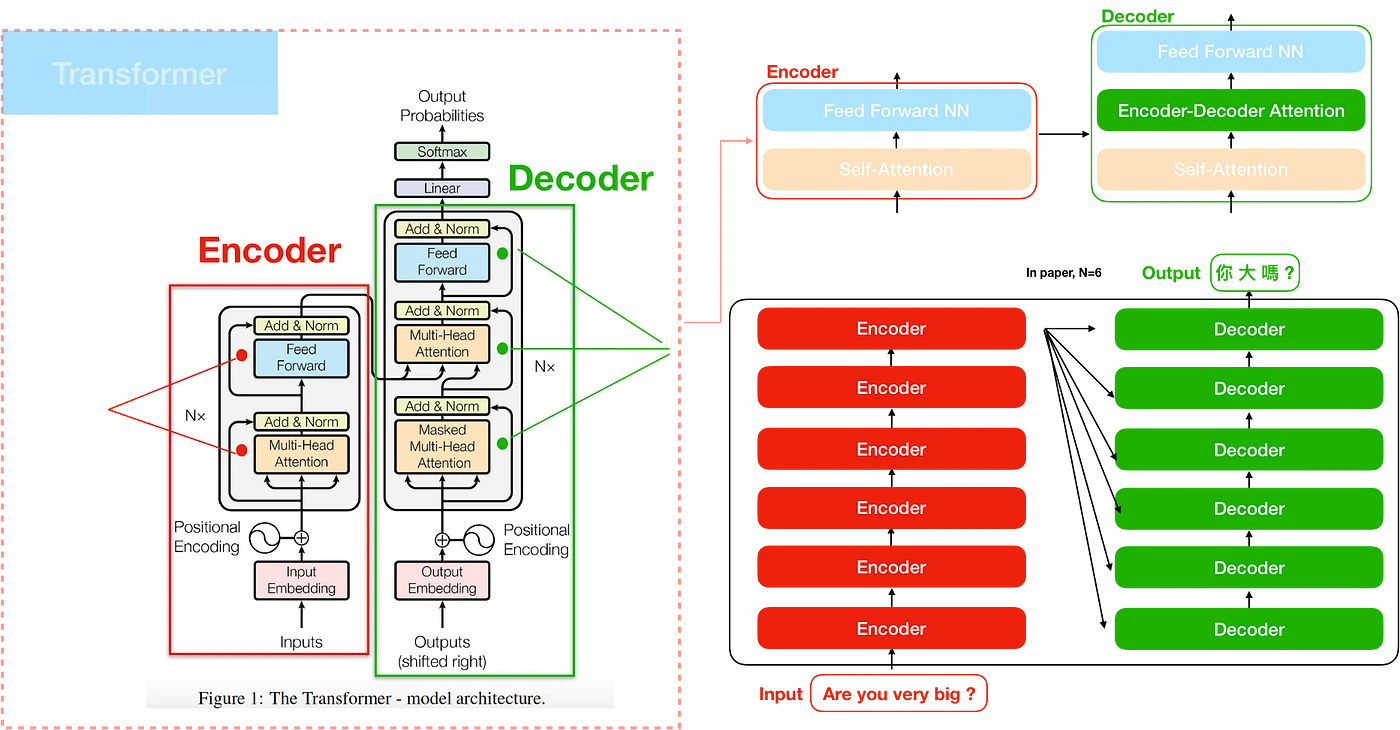
讲模型架构,我推荐从原文的图开始看。
![]()
从inputs开始,把所有东西整理一遍。
Embedding
图中最下方,有一个粉色的embedding(嵌入),以及posiitonal embedding(位置编码)分别对inputs和outputs进行处理。这里的outputs并不是指最终的输出,这一点下文还会讲到。
嵌入的过程非常简单,就是将字符(实际是语义单元token)映射为一个向量。此前,还有一个tokenize方法,将句子分解为tokens,该部分本文不多解释。映射方法就是“查表”,有一个表,纬度为[输入集的所有token种类数]x[模型输入纬度]。比如,假设输入为汉字,且假设一个字是一个token。常用字5000字,对应的嵌入矩阵大小为2000x512,后者为transformer网络输入纬度。 获得嵌入矩阵,一方面可以考虑预定义。随机初始化的嵌入也是有效的,通过进行机器学习(如Word2Vec)可以得到更优的嵌入。但是另一方面考虑到transformer本身就在学习语言的关系,直接随机初始化,然后在优化过程中把这个矩阵带着一起优化了就可以。
完成基本嵌入以后,还要进行位置嵌入。直观上,这是考虑到同一个token在不同位置上的意思分布可能存在不同,把位置信息也嵌入到向量中。在经典Transformer中,位置信息直接使用公式进行嵌入,公式为
pos是token所在的index,而i从0到-1,计算得到(原文为512)长度的向量,和基本的嵌入向量相加。考虑到下文我们需要进行实现,此处有一个显而易见的实现思路。对于某个模型,位置编码显然是固定的,无需重复计算,可以初始化储存后直接读取。
假设输入为n个token,经过embedding以后,形状变为(n, 768)。此处未考虑batch计算。
示例实现:
123456789101112131415161718class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_len):
super().__init__()
self.positional_encoding = self._generate_positional_encoding(d_model, max_seq_len)
# 虽然上面提了,但是这里没有实现储存。。。
def _generate_positional_encoding(self, d_model, max_seq_len):
pos = np.arange(max_seq_len).reshape(-1, 1)
i = np.arange(d_model).reshape(1, -1)
angle_rates = 1 / np.power(10000, (2 * (i // 2)) / d_model)
pos_encoding = pos * angle_rates
pos_encoding[:, 0::2] = np.sin(pos_encoding[:, 0::2]) # 偶数列
pos_encoding[:, 1::2] = np.cos(pos_encoding[:, 1::2]) # 奇数列
return torch.tensor(pos_encoding, dtype=torch.float32)
def forward(self, x):
seq_len = x.size(1)
return x + self.positional_encoding[:seq_len, :]
Encoder
左边的整个灰色部分都是所谓的Encoder。我们依旧从下往上看。
多头注意力
首先是Multi-Head Attention。该部分是本文核心,结构如图。
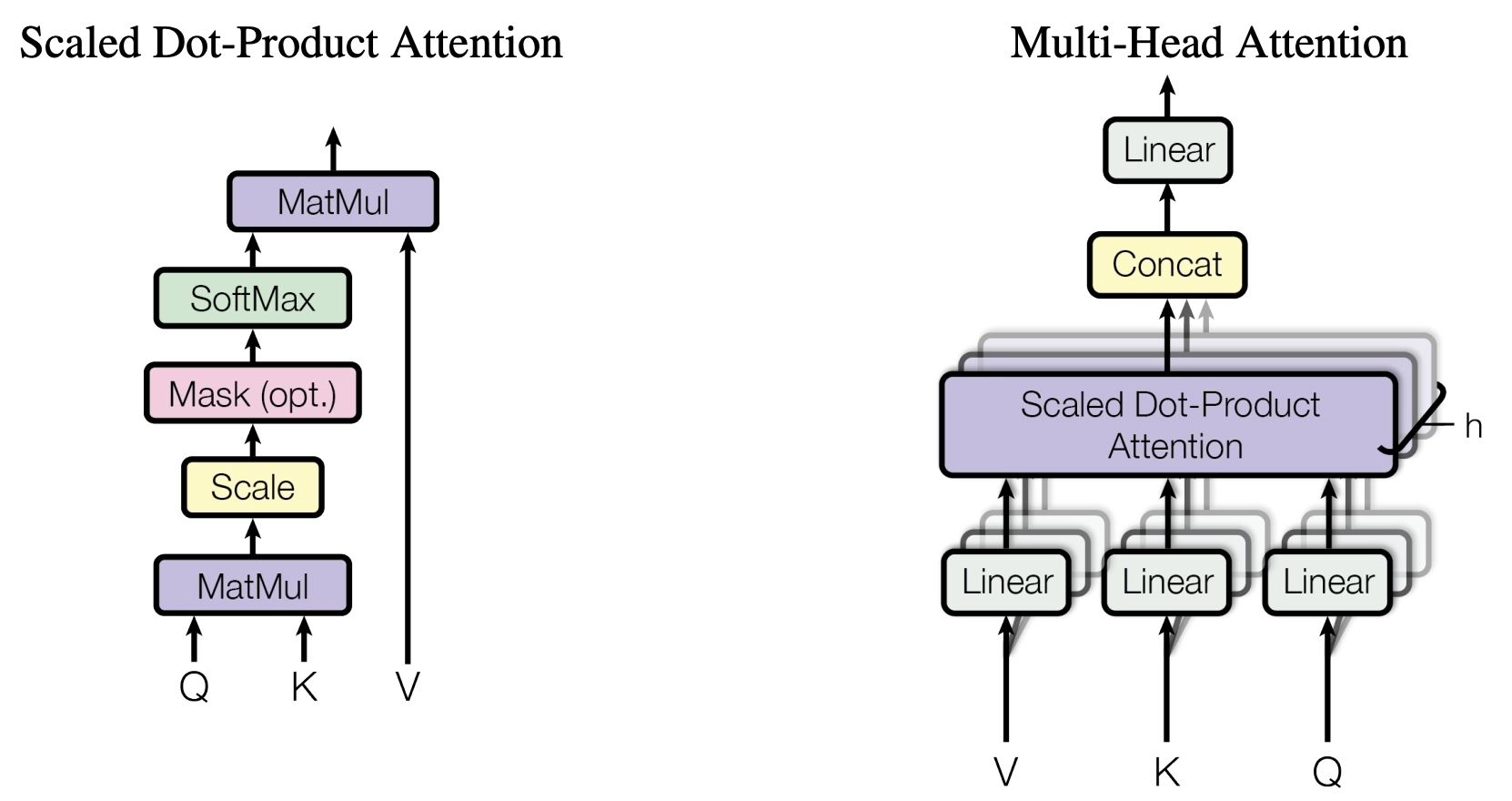
单独看左边的Attention,输入是Q、K、V,对应查询,键,值。这三个向量的维度是一样的,都是,都是由Embedding以后的输入得到的,列数相同。首先Q,K进行矩阵相乘,然后除以列数的平方根来防止值过大。然后进行softmax,得到权重。最后,权重和V相乘,得到输出。表达为公式则为
是单个头的模型维度。由于多头时输出是拼接的,所以维度会相应变小。 这里有点疑惑的一个点是既然使用了softmax,为什么前面还要Scaling。不是都回到(0,1)上了吗。我觉得这主要是因为防止出现过大的绝对值,导致softmax中除了最大项,其他项都接近0,而且梯度变小。
多头注意力
从上图可以看到,多头就是将单头的输出进行拼接,然后前后加上线形层。
从整体架构图中可以看到,Encoder处的多头注意力输入就是嵌入后的输入。对于多头中的某一头而言,生成K,Q,V的三个线形变换均为到的线性变换。不过实际实现时,合并在一次变换里就可以了。多头注意力的输出是到的线性变换,输出维度不变。
从含义上来讲,Q是查询,K是键值。Encoder部分注意力的Q,K点积结果是一个宽度为Token数的方阵,希望描述的是Token序列中每个Token对其他Token的重要程度。注意力实际就是这个意思。这个矩阵再和V相乘,得到的是每个Token在同一句中其他Token的影响下的表示,或者说在注意力作用下的结果。
示例实现:
123456789101112131415161718192021222324252627282930313233class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
self.num_heads = num_heads
self.d_head = d_model // num_heads
self.q_linear = nn.Linear(d_model, d_model)
self.k_linear = nn.Linear(d_model, d_model)
self.v_linear = nn.Linear(d_model, d_model)
self.out_linear = nn.Linear(d_model, d_model)
def forward(self, q, k, v):
batch_size = q.size(0)
# 线性变换
q = self.q_linear(q).view(batch_size, -1, self.num_heads, self.d_head).transpose(1, 2) # 1, 8, n, 64 将head数transpose到前面
k = self.k_linear(k).view(batch_size, -1, self.num_heads, self.d_head).transpose(1, 2)
v = self.v_linear(v).view(batch_size, -1, self.num_heads, self.d_head).transpose(1, 2)
# Scaled Dot-Product Attention
scores = torch.matmul(q, k.transpose(-2, -1)) / np.sqrt(self.d_head)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attention_weights = F.softmax(scores, dim=-1)
attention_output = torch.matmul(attention_weights, v) # 1, 8, n, 64
# 合并多头
attention_output = attention_output.transpose(1, 2).contiguous().view(batch_size, -1, self.num_heads * self.d_head) # 由于之前转置,需要显示调用contiguous才能使用view。这里的view和concatenate等效
return self.out_linear(attention_output)
这里把mask也实现了。mask在解码器中才会提到。
ADD & Norm
这就是一个残差模块,把输入和多头注意力的结果直接相加,然后进行LayerNorm。LayerNorm是对每个样本的每个特征进行归一化,即最后一个维度。之前的文章中已经详细解释过,和BatchNorm的区别在于归一化的维度。其余部分的Add & Norm也是类似的。
Feed Forward
就是一个线性层,增强网络表达能力,没有什么特别的。我相信有人的确就此进行研究,比如去掉以后的效果,但我没有见过。原文中使用ReLU激活函数,但是一般认为NLP中使用ReLU更容易导致神经元失活。流行的激活函数是GeGLU。
12345678class FeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super().__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
def forward(self, x):
return self.linear2(F.relu(self.linear1(x)))
以上,整个Encoder的实现如下:
123456789101112131415161718192021222324252627class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff):
super().__init__()
self.attention = MultiHeadAttention(d_model, num_heads)
self.norm1 = nn.LayerNorm(d_model)
self.ffn = FeedForward(d_model, d_ff)
self.norm2 = nn.LayerNorm(d_model)
def forward(self, x, mask=None):
attention_output = self.attention(x, x, x, mask)
x = self.norm1(x + attention_output)
ffn_output = self.ffn(x)
return self.norm2(x + ffn_output)
class TransformerEncoder(nn.Module):
def __init__(self, vocab_size, d_model, num_heads, num_layers, max_seq_len, d_ff=2048):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.positional_encoding = PositionalEncoding(d_model, max_seq_len)
self.layers = nn.ModuleList([TransformerEncoderLayer(d_model, num_heads, d_ff) for _ in range(num_layers)])
def forward(self, x, mask=None):
x = self.embedding(x)
x = self.positional_encoding(x)
for layer in self.layers:
x = layer(x, mask)
return x
实现已经考虑多Layer的Transformer。
Decoder
所有的模块均已经讲过,只有一处,就是使用mask的注意力。关于使用mask,还需要从Decoder的输入讲起。
Decoder的输入是整个模型的输出。这么说起来听上去很奇怪,但因为Transformer事实上一次前向只能转换一个长度,即预测下一个Token。所以Decoder的输入是上一轮的输出。比如,如果一个翻译任务,是将
为了快速的实现训练,我们不会一轮一轮的去算,而是一次全算完直接优化。于是我们就需要一个阶梯型的mask,得到一个长度递增的真值output矩阵。不过实现的时候把mask当作一般矩阵即可。生成mask还是在外部比较灵活。
mask已经在上文实现过,Decoder的实现如下:
12345678910111213141516171819202122232425262728293031323334class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff):
super().__init__()
self.self_attention = MultiHeadAttention(d_model, num_heads)
self.norm1 = nn.LayerNorm(d_model)
self.cross_attention = MultiHeadAttention(d_model, num_heads)
self.norm2 = nn.LayerNorm(d_model)
self.ffn = FeedForward(d_model, d_ff)
self.norm3 = nn.LayerNorm(d_model)
def forward(self, x, encoder_output, tgt_mask=None, memory_mask=None):
self_attention_output = self.self_attention(x, x, x, tgt_mask)
x = self.norm1(x + self_attention_output)
cross_attention_output = self.cross_attention(x, encoder_output, encoder_output, memory_mask)
x = self.norm2(x + cross_attention_output)
ffn_output = self.ffn(x)
return self.norm3(x + ffn_output)
class TransformerDecoder(nn.Module):
def __init__(self, vocab_size, d_model, num_heads, num_layers, max_seq_len, d_ff):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.positional_encoding = PositionalEncoding(d_model, max_seq_len)
self.layers = nn.ModuleList([TransformerDecoderLayer(d_model, num_heads, d_ff) for _ in range(num_layers)])
self.out_proj = nn.Linear(d_model, vocab_size)
def forward(self, x, encoder_output, tgt_mask=None, memory_mask=None):
x = self.embedding(x)
x = self.positional_encoding(x)
for layer in self.layers:
x = layer(x, encoder_output, tgt_mask, memory_mask)
logits = self.out_proj(x)
probabilities = F.softmax(logits, dim=-1)
return probabilities
完整实现
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149150151import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
# 超参数
d_model = 512
num_heads = 8
num_layers = 6
max_seq_len = 50
vocab_size = 10000
d_ff = 2048
# Tokenizer
def tokenize(text):
return [ord(c) % vocab_size for c in text] # 字符级别 Tokenizer
def detokenize(tokens):
return ''.join([chr(t) for t in tokens])
# 位置编码
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_len):
super().__init__()
self.positional_encoding = self._generate_positional_encoding(d_model, max_seq_len)
def _generate_positional_encoding(self, d_model, max_seq_len):
pos = np.arange(max_seq_len).reshape(-1, 1)
i = np.arange(d_model).reshape(1, -1)
angle_rates = 1 / np.power(10000, (2 * (i // 2)) / d_model)
pos_encoding = pos * angle_rates
pos_encoding[:, 0::2] = np.sin(pos_encoding[:, 0::2]) # 偶数列
pos_encoding[:, 1::2] = np.cos(pos_encoding[:, 1::2]) # 奇数列
return torch.tensor(pos_encoding, dtype=torch.float32)
def forward(self, x):
seq_len = x.size(1)
return x + self.positional_encoding[:seq_len, :]
# 多头注意力机制
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
self.num_heads = num_heads
self.d_head = d_model // num_heads
self.q_linear = nn.Linear(d_model, d_model)
self.k_linear = nn.Linear(d_model, d_model)
self.v_linear = nn.Linear(d_model, d_model)
self.out_linear = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
batch_size = q.size(0)
q = self.q_linear(q).view(batch_size, -1, self.num_heads, self.d_head).transpose(1, 2)
k = self.k_linear(k).view(batch_size, -1, self.num_heads, self.d_head).transpose(1, 2)
v = self.v_linear(v).view(batch_size, -1, self.num_heads, self.d_head).transpose(1, 2)
scores = torch.matmul(q, k.transpose(-2, -1)) / np.sqrt(self.d_head)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attention_weights = F.softmax(scores, dim=-1)
attention_output = torch.matmul(attention_weights, v)
attention_output = attention_output.transpose(1, 2).contiguous().view(batch_size, -1, self.num_heads * self.d_head)
return self.out_linear(attention_output)
# 前向传播网络
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super().__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
def forward(self, x):
return self.linear2(F.relu(self.linear1(x)))
# 编码器层
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff):
super().__init__()
self.attention = MultiHeadAttention(d_model, num_heads)
self.norm1 = nn.LayerNorm(d_model)
self.ffn = FeedForward(d_model, d_ff)
self.norm2 = nn.LayerNorm(d_model)
def forward(self, x, mask=None):
attention_output = self.attention(x, x, x, mask)
x = self.norm1(x + attention_output)
ffn_output = self.ffn(x)
return self.norm2(x + ffn_output)
# 解码器层
class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff):
super().__init__()
self.self_attention = MultiHeadAttention(d_model, num_heads)
self.norm1 = nn.LayerNorm(d_model)
self.cross_attention = MultiHeadAttention(d_model, num_heads)
self.norm2 = nn.LayerNorm(d_model)
self.ffn = FeedForward(d_model, d_ff)
self.norm3 = nn.LayerNorm(d_model)
def forward(self, x, encoder_output, tgt_mask=None, memory_mask=None):
self_attention_output = self.self_attention(x, x, x, tgt_mask)
x = self.norm1(x + self_attention_output)
cross_attention_output = self.cross_attention(x, encoder_output, encoder_output, memory_mask)
x = self.norm2(x + cross_attention_output)
ffn_output = self.ffn(x)
return self.norm3(x + ffn_output)
# 编码器
class TransformerEncoder(nn.Module):
def __init__(self, vocab_size, d_model, num_heads, num_layers, max_seq_len, d_ff):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.positional_encoding = PositionalEncoding(d_model, max_seq_len)
self.layers = nn.ModuleList([TransformerEncoderLayer(d_model, num_heads, d_ff) for _ in range(num_layers)])
def forward(self, x, mask=None):
x = self.embedding(x)
x = self.positional_encoding(x)
for layer in self.layers:
x = layer(x, mask)
return x
# 解码器
class TransformerDecoder(nn.Module):
def __init__(self, vocab_size, d_model, num_heads, num_layers, max_seq_len, d_ff):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.positional_encoding = PositionalEncoding(d_model, max_seq_len)
self.layers = nn.ModuleList([TransformerDecoderLayer(d_model, num_heads, d_ff) for _ in range(num_layers)])
self.out_proj = nn.Linear(d_model, vocab_size)
def forward(self, x, encoder_output, tgt_mask=None, memory_mask=None):
x = self.embedding(x)
x = self.positional_encoding(x)
for layer in self.layers:
x = layer(x, encoder_output, tgt_mask, memory_mask)
return self.out_proj(x)
# 完整 Transformer
class Transformer(nn.Module):
def __init__(self, vocab_size, d_model, num_heads, num_layers, max_seq_len, d_ff):
super().__init__()
self.encoder = TransformerEncoder(vocab_size, d_model, num_heads, num_layers, max_seq_len, d_ff)
self.decoder = TransformerDecoder(vocab_size, d_model, num_heads, num_layers, max_seq_len, d_ff)
def forward(self, src, tgt, src_mask=None, tgt_mask=None, memory_mask=None):
encoder_output = self.encoder(src, src_mask)
decoder_output = self.decoder(tgt, encoder_output, tgt_mask, memory_mask)
return decoder_output
常见问题讨论和面试题
然而我暂时没有在准备面试,这段后补,目前直接看参考链接。